NOSQL
NoSQL,泛指非关系型的数据库。随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题(这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展)。
互联网时代背景下关系型数据架构的局限性
-首先时单机时代关系型数据库的局限性:
1、单机能储存的数据量有限,但数据量的总大小达到一定规模时,一个机器就放不下这些数据了。
2、为了提高查询速度,我们会为数据建立索引(B+ Tree),但索引也需要占据储存空间的.
3、访问量(读写混合)一个实例不能承受的时候,需要进行读写分离,主从复制等处理。
-到了后面为了降低一些经常性的操作比如查询对数据库访问的压力,我们在传统的互联网架构的DAO层和数据层中间加了一个缓存。同时进行数据库的垂直拆分,来减轻访问所带来的IO竞争。
-后续为了数据的安全性和减轻数据库的访问压力,进行了数据库的主从复制和读写分离。
-随着数据量的增加,单个数据库能存储的数据量有限,又通过分表分库、水平拆分和建立数据库集群等方式来减低储存压力,同时减低数据访问的压力。但关系型数据架构依然存在瓶颈,再扩展性上也出现了瓶颈。
-今天我们的数据架构已经演变成用户发送访问请求,请求经过防火墙、负载均衡主机(通过NGIX反向代理),再到服务器集群,再到数据库集群(这里面的数据库会根据处理的不同业务进行拆分,有处理图片的有处理流媒体的等等)。
NOSQL的特性
1、易扩展。因为去掉了关系数据库的关系型特征,数据之间没有关系,所以非常容易扩展。 2、大数据量高性能。具有非常高的读写性能。同时NOSQL的Cache时记录级的,是一种细粒度的Cache,所以缓存性能也非常高,不像MySQL使用的query cache,每次表更新cache就会失效。 3、多样灵活的数据模型。NOSQL无需事先为要存储的数据建立字段,可以随时存储自定义的数据格式。
RDBMS和NOSQL的对比
RDBMS
-高度组织花结构化数据
-结构化查询语言
-数据和关系狗存储再单独的表中。
-数据操纵语言,数据定义语言。
-严格的一致性
-基础事务
NOSQL
-没有声明性查询语言
-没有预定义的模式
-最终一致性,非ACID属性
-非结构化和不可预知的数据
-CAP定理
-高性能,高可用性和高伸缩性
目前互联网技术所面临的难点和解决方案
通过前面的描述我们知道目前互联网数据架构呈现出多数据源多数据类型的特征。
多数据源多数据类型给我们开发带来了下面几个难点:
1、数据类型多样性;2、数据源多样性和变化重构;3、数据源改造而数据服务平台不需要大面积重构;
以上难点总结起来就是我们在开发中需要针对不同的数据源和数据类型进行单独的处理,没办法进行统一的处理,而且在生产环境中单个数据源出现问题将导致整个系统的运作出现问题。
针对上面的问题,其解决方法就是建立统一的数据平台服务层(UDSL)。这个统一数据平台的作用主要有以下三个方面。1、模型数据映射,实现业务模型各属性和底层不同类型数据源的模型数据映射;2、统一的查询和更新API,提供了基于业务模型和统一的查询和更新的API,简化网站应用跨不同数据源的开发模式;3、提供以下性能优化策略:字段延迟加载,按需返回设置;基于热点缓存平台的二级缓存;异步并行的查询数据;异步并行加载模型中来自不同数据源的字段;并发保护(拒绝访问频率过高的主机IP或IP段);过滤高危的查询(例如会导致数据库崩溃的全表扫描)。
NOSQL数据模型的简介
传统的关系型数据库设计是通过ER图描述,关系型数据库的设计围绕这表之间的一对一、一对多、多对多关系、范式描述和主外键等。
NOSQL非关系型数据库的设计通过BSON数据类型来描述,BSON是JSON数据的一种,BSON数据类型是通过json串描述各种表信息的。
随着互联网分布式系统的发展,关系型数据库的这种数据模型已经不能很好满足高并发访问的需求,比如我们在编写sql查询语句的时候,如果涉及多表关联查询,就需要通过join语句从多个数据表中查询相关信息,这在高并发访问的分布式系统下是效率非常低的。而非关系型数据库的数据模型只需要通过一条语句获取应该json串进行解析即可。
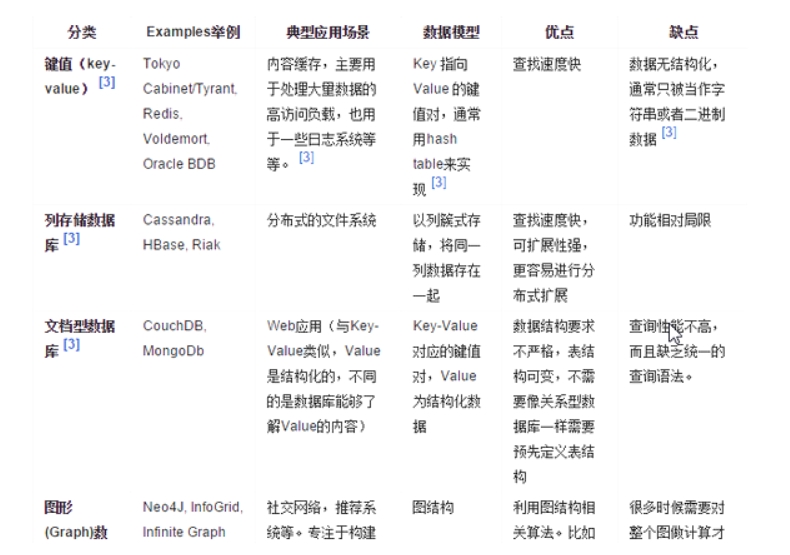
NOSQL数据库的四大分类
NOSQL聚合模型的常用类型包括:KV键值、Bson、列族、图形;
分布式数据库CAP原理
CAP:
Consistency(强一致性);
Availability(可用性);
Partition tolerance(分区容错性);
CAP不像ACID都需要满足,它只能满足三个中的两个,所以根据CAP原理可以将NOSQL数据库分为三种:
CA—单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大(传统关系型数据库);
CP—满足一致性,分区容忍的系统,通常性能不是特别高(Redis,Mongodb);
AP—满足可用性,可分区容忍性的系统,通常可能对一致性要求低一些(大多数网站架构的选择);
在分布式存储系统中,分区容忍性事必须实现的,因为当前的网络硬件肯定会出现延迟丢包等问题。
CAP+Base
BASE是为了解决关系数据库强一致性引起的问题而引起的可用性降低而提出的解决方案。
基本可用(Basically Avaliable);软状态(Soft state);最终一致(Eventually consistent);
它的思想是通过让系统放松对某一时刻数据一致性的要求来换取系统整体伸缩性和性能上的改变;
分布式和集群
分布式:不同的多台服务器上面部署不同的服务模块,他们之间通过RPC/RMI之间通信和调用,对外提供服务和组内协作;
集群:不同的多台服务器上面部署相同的服务模块,通过分布式调度软件进行统一的调度,对外提供服务和访问。