data structure and algorithm
我希望每个人对算法和数据结构是什么有一个深刻的认识,所以我们会在每一篇的文章的开始给你灌输下面的这些知识点:
1、数据结构是一门研究组织数据方式的学科,有了编程语言也就有了数据结构,学好数据结构可以让你写出更漂亮更高效的代码(时间复杂度和空间复杂度);
2、算法其实就是解决我们生活中遇到的问题的计算方法;
3、程序=数据结构+算法;要学好数据结构和算法就要在日常生活中把遇到的问题尝试用程序去解决
4、数据结构是实现一个算法的基础,所以想要学好算法,需要把数据结构学到位;
5、数据结构分为线性结构和非线性结构;线性结构的特点是数据元素之间存在一对一的线性关系;
6、线性结构又有顺序存储结构和链式存储结构两种的存储结构,顺序存储结构中存储元素是连续的,而链式存储结构中存储元素不一定是连续的;
排序算法
排序算法是将一组数据,依指定的顺序进行排列的过程;
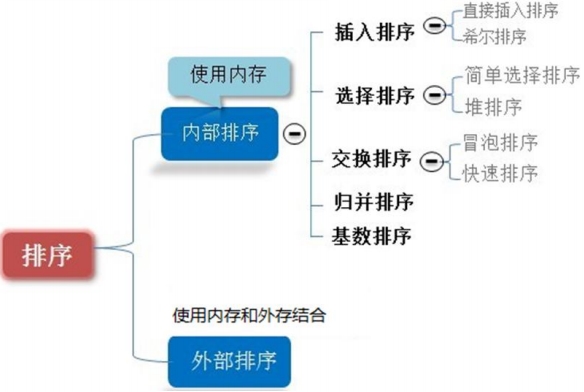
排序分内部排序和外部排序两类,内部排序是指将需要处理的所有数据都加载到内部存储器(内存)中进行排序;外部排序是指由于数据量过大,无法全部加载到内存中,需要借助外部存储(文件等)进行排序;
冒泡排序
基本思想:依次比较相邻的两个数,将小数放在前面,大数放在后面。即在第一趟:首先比较第1个和第2个数,将小数放前,大数放后。然后比较第2个数和第3个数,将小数放前,大数放后,如此继续,直至比较最后两个数,将小数放前,大数放后。重复第一趟步骤,直至全部排序完成。
优化:因为排序的过程中,各元素不断接近自己的位置,如果一趟比较下来没有进行过交换,就说明序列已经有序,因此要在排序过程中设置一个flag判断元素是否进行过交换,从而减少不必要的比较;
代码实现:
/*
实现步骤:
1、对前n-1个元素进行遍历,从头到尾对前n-1-i个元素依次比较两个元素的大小,进行交换把大的元素往后推;
2、可以设置一个Boolean值,如果在一趟遍历中有进行交换,则将Boolean改为true,在每趟遍历的最后判断Boolean是否为true,是的话把Boolean改为false进行下一趟遍历,否则直接结束遍历;
*/
public class MaoPao {
public static void main(String[] args) {
int[] ins=new int[80000];
for(int i=0;i<80000;i++){
ins[i]= (int) (Math.random()*80000);
}
long start=System.nanoTime();
maopao(ins);
long end=System.nanoTime();
System.out.println(end-start);
}
public static void maopao(int[] ins){
for(int i=0;i<ins.length-1;i++){
boolean flag=false;
for(int j=0;j<ins.length-1-i;j++){
if(ins[j]>ins[j+1]){
int temp=ins[j];
ins[j]=ins[j+1];
ins[j+1]=temp;
flag=true;
}
}
if(flag==false)
break;
}
}
}
直接选择排序
基本思路:对于具有 n 个记录的无序表遍历 n-1 次,第 i 次从无序表中第 i 个记录开始,找出后序关键字中最小的记录,然后放置在第 i 的位置上。
代码实现:
/*
实现步骤:
1、对前n-1个元素进行遍历,选出后面的n-i个元素中最小的元素,与第i个元素进行交换
*/
public static void xuanze(int[] ins){
for(int i=0;i<ins.length-1;i++){
int index=i;
int min=ins[i];
for(int j=i+1;j<ins.length;j++){
if(min>ins[j]){
min=ins[j];
index=j;
}
};
if(index!=i){
ins[index]=ins[i];
ins[i]=min;
}
}
}
直接插入排序
基本思想:把n个待排序的元素看成一个有序表和一个无序表,开始时有序表中只有一个元素,无序表中有n-1个元素;排序过程即每次从无序表中取出第一个元素,将它插入到有序表中,使之成为新的有序表,重复n-1次完成整个排序过程。
代码实现:
/*
实现步骤:
1、从第二个元素依次向后进行循环遍历,每一趟遍历结束之后前i+1个元素就为有序数组
2、让当前元素与前面的有序数组从后到前依次进行比较和交换,将当前值插入到一个合适的位置使得前面的数组依然实现有序;
*/
public static void charu(int[] ins){
for(int i=1;i<ins.length;i++){
int index=i-1;
int val=ins[i];
while(index>=0 && val<ins[index]){
ins[index+1]=ins[index];
index--;
}
ins[index+1]=val;
}
}
希尔排序
希尔排序是在直接插入排序的基础上提出的,因为直接插入排序在某些特殊情况下会非常低效,比如我们在很小的数初始位置在数组的后面的时候,需要进行多次比较进行多次移动才能实现有序;希尔排序的提出就是为了避免这种极端情况所带来的效率低下问题;
基本思想:希尔排序在数组中采用跳跃式分组的策略,通过某个增量将数组元素划分为若干组,然后分组进行插入排序,随后逐步缩小增量,继续按组进行插入排序操作,直至增量为1。希尔排序通过这种策略使得整个数组在初始阶段达到从宏观上看基本有序,小的基本在前,大的基本在后。然后缩小增量,到增量为1时,其实多数情况下只需微调即可,不会涉及过多的数据移动。
希尔排序在对有序序列插入时,可以采用交换法和移动法两种,下面我们将实现这两种方式并进行排序速度的测试,看看哪种算法更优或者说在哪些情况下使用哪种算法更优;
交换法实现希尔排序:
/*
1、循环遍历计算增量,第一次增量为(当前数组长度)/2,增量的计算方式为(当前增量)/2,增量代表的意义为将当前数组按照下标间隔为增量大小将数组分为增量大小个数组;
2、对各个分出来的增量数组进行冒泡排序;
*/
public static void xier1(int[] ins){
int temp;
for(int z=ins.length/2;z>0;z/=2){
for(int i=z;i<ins.length;i++){
for(int j=i-z;j>=0;j-=z){
if(ins[j]>ins[j+z]){
temp=ins[j];
ins[j]=ins[j+z];
ins[j+z]=temp;
}
}
}
}
}
移动法实现希尔排序:
/*
实现步骤:
1、循环遍历计算增量,第一次增量为(当前数组长度)/2,增量的计算方式为(当前增量)/2,增量代表的意义为将当前数组按照下标间隔为增量大小将数组分为增量大小个数组;
2、对各个分出来的增量数组进行直接插入排序;
*/
public static void xier2(int[] ins){
for(int z=ins.length/2;z>0;z/=2) {
for (int i = z; i < ins.length; i++) {
int index=i;
int val=ins[i];
if(ins[index]<ins[index-z]){
while(index-z>=0 && ins[index]<ins[index-z]){
ins[index]=ins[index-z];
index-=z;
}
ins[index]=val;
}
}
}
}
通过速度测试我们知道,由于交换法需要进行多次的交换,所以它的效率相对移动法会更低
快速排序
快速排序是对冒泡排序的一种改进。
基本思想:通过一次排序将整个无序表分成相互独立的两部分,其中一部分中的数据都比另一部分中包含的数据的值小,然后继续沿用此方法分别对两部分进行同样的操作,直到每一个小部分不可再分,所得到的整个序列就成为了有序序列。
快速排序是所有时间复杂度相同的排序方法中性能最好的排序算法。快速排序在序列中元素很少时,效率将比较低,不如插入排序,因此一般在拆分到序列中元素很少时使用插入排序,这样可以提高整体效率。
代码实现:
/*
实现步骤:
1、获取中轴值:常见获取中轴值的方式:取中法、取末位值法、三数中值分割法;
2、进行循环遍历,直到左下标比右下标大;
3、循环遍历左下标/右下标,不断向右/左移动,直到找到其元素值大于/小于中轴值的下标;
4、判断当前左下标是否大于右下标,如果是的话结束遍历;
5、交换两个下标元素;
6、判断交换的两个下标元素是否等于中轴值,如果交换前右下标等于中轴值,也就是说交换后左下标就是中轴值,其左边的元素都小于它,而右下标的值此时是大于它的,因为交换前已经进行了比较,所以需要将右下标左移一位之后继续进行遍历;判断交换前左下标等于中轴值后的动作逻辑是一样的,这里就不进行赘述;
7、结束遍历之后,此时中轴值的左边元素都大于它,右边元素都小于它,这时候首先判断左右下标是否相等,相等的话要进行左加右减操作,不然会出现栈溢出,因为我们后续会递归对中轴值左右边的数组进行新一轮的快速排序,当左右下标相等时,最终递归调用的数组中会出现重复元素,从而导致最终和栈溢出和计算结果的错误;
8、递归对中轴值左右两边的数组进行快速排序;
*/
public static void quickSort(int[] arr,int left, int right) {
int l = left; //左下标
int r = right; //右下标
//pivot 中轴值
int pivot = arr[(left + right) / 2];
int temp = 0; //临时变量,作为交换时使用
//while循环的目的是让比pivot 值小放到左边
//比pivot 值大放到右边
while( l < r) {
//在pivot的左边一直找,找到大于等于pivot值,才退出
while( arr[l] < pivot) {
l += 1;
}
//在pivot的右边一直找,找到小于等于pivot值,才退出
while(arr[r] > pivot) {
r -= 1;
}
//如果l >= r说明pivot 的左右两的值,已经按照左边全部是
//小于等于pivot值,右边全部是大于等于pivot值
if( l >= r) {
break;
}
//交换
temp = arr[l];
arr[l] = arr[r];
arr[r] = temp;
//如果交换完后,发现这个arr[l] == pivot值 相等 r--, 前移
if(arr[l] == pivot) {
r -= 1;
}
//如果交换完后,发现这个arr[r] == pivot值 相等 l++, 后移
if(arr[r] == pivot) {
l += 1;
}
}
// 如果 l == r, 必须l++, r--, 否则为出现栈溢出
if (l == r) {
l += 1;
r -= 1;
}
//向左递归
if(left < r) {
quickSort(arr, left, r);
}
//向右递归
if(right > l) {
quickSort(arr, l, right);
}
}
其他优化的获取中轴值的方式:三数中值分割法
public static int mid(int[] ins,int left,int right){
int mid=left+(right-left)/2;
int temp;
if(ins[mid]>ins[right]){
temp=ins[mid];
ins[mid]=ins[right];
ins[right]=temp;
}
if(ins[left]>ins[right]){
temp=ins[left];
ins[left]=ins[right];
ins[right]=temp;
}
if(ins[mid]>ins[left]){
temp=ins[left];
ins[left]=ins[mid];
ins[mid]=temp;
}
return ins[left];
}
归并排序
基本思想:归并排序是利用归并的思想实现的排序方法,该算法采用经典的分治策略,分的阶段将问题分成一些小的问题然后递归求解,而治的阶段则将分的阶段得到的各答案“修补”在一起,即分而治之;归并排序合并两个有序字段,按原字段的顺序进行比较排序,当某一字段都比较完之后,另一字段剩余的部分都放在尾部。
代码实现:
/*
实现步骤:
分:
1、获取当前数组的中点,把数组一分为二,依次递归调用其左右子数组,直到数组不能再分;
治:
2、当数组划分到不能再分的情况,也就是每个数组只有一个元素,这个时候数组就是有序的,通过回溯从后往前继续依次有序合并两个划分的数组;
3、有序合并的方式:对划分的两个有序数组从头到尾进行比较,把较小的元素优先添加到合并的数组中,最终就能得到一个有序的合并数组;
*/
public static void guibing(int[] ins,int left,int right,int[] temp){
if(left<right){
int mid=(left+right)/2;
guibing(ins,left,mid,temp);
guibing(ins,mid+1,right,temp);
merge(ins,left,mid,right,temp);
}
}
public static void merge(int[] ins,int left,int mid,int right,int[] temp){
int l=left;
int r=mid+1;
int t=0;
while(l<=mid && r<=right){
if(ins[l]<ins[r]){
temp[t]=ins[l];
t++;
l++;
}else{
temp[t]=ins[r];
t++;
r++;
}
}
if(l<=mid){
temp[t]=ins[l];
t++;
l++;
}
if(r<=right){
temp[t]=ins[r];
t++;
r++;
}
t=0;
int index=left;
while(index<=right){
ins[index]=temp[t];
index++;
t++;
}
}
基数排序
基本思想:将所有待比较数值(正整数)统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列。
基数排序算法是效率高的稳定性排序算法,它是桶排序的扩展。
代码实现:
/*
实现步骤:
1、定义一个row=10的二维数组来模拟10个桶,然后定义一个长度为10的一维数组来记录每个桶所放置的元素个数;
2、循环待排序数组的所有元素,找出最大值,并获取最大值的最高位数;
3、根据位数进行遍历,如果最高位为个位则进行一趟遍历,如果为十位则进行两趟,依次类推;
4、在每趟遍历中,以及比较的位数把待排序的元素依次放入对应的桶,比如遍历的是个位的时候,个位为0的元素放入一号桶,为1的放入二号桶,依次类推,每放进一个元素就要把记录对应桶中元素个数的数组+1;
5、在元素摆放完毕之后,从一号台到十号桶依次把桶中元素按顺序放回原数组中,然后进行新一轮的遍历;
6、遍历完成后最终原数组中的元素就是有序的了;
*/
public static void jishu(int[] ins){
int[][] tong=new int[10][ins.length];
int[] tongshu=new int[10];
int max=ins[0];
for(int i=0;i<ins.length;i++){
if(ins[i]>max){
max=ins[i];
}
}
int maxlenght=(max+"").length();
for(int i=0,n=1;i<maxlenght;i++,n*=10){
for(int j=0;j<ins.length;j++){
int wei=ins[j]/n%10;
tong[wei][tongshu[wei]]=ins[j];
tongshu[wei]++;
}
int index=0;
for(int z=0;z<tongshu.length;z++){
if(tongshu[z]!=0){
for(int t=0;t<tongshu[z];t++){
ins[index]=tong[z][t];
index++;
}
}
tongshu[z]=0;
}
}
}
堆排序
基本思想:通过将无序表转化为堆(堆用完全二叉树表示),可以直接找到表中最大值或者最小值,然后将其提取出来,令剩余的记录再重建一个堆(筛选的过程),取出次大值或者次小值,如此反复执行就可以得到一个有序序列,此过程为堆排序。
堆排序有大顶堆和小顶堆两个概念,大顶堆即根节点大于子节点,小顶堆即根节点小于子节点,想进行升序就进行大顶堆排序,降序就进行小顶堆排序;
代码实现:
/*
实现步骤:
1、定义一个调整的方法,对父节点及其所有的子节点进行堆排序;
2、调整方法的实现步骤:获取要调整的父节点的下标、以及数组和数组大小的信息,然后依次循环遍历所要调整的父节点的所有子节点,获取左子节点的方式是(根节点下标)*2+1,首先判断子节点是否存在和比较两个子节点的大小,返回比较大的子节点的下标,然后再比较较大的子节点与父节点的大小,如果子节点较大的话则交换元素,然后让较大的子节点成为新的父节点,重复上述步骤,最终跳出循环前要让当前父节点的值替换成最初父节点的值;如果父节点较大的话则终止循环;
3、第一遍堆排序要对所有的非叶子节点都进行调整,根据(数组长度)/2-1获取最后一个非叶子节点,循环向上进行调整;
4、完成第一遍堆排序之后,接下来的堆排序就只需要对根节点进行调整,因为我们每一遍堆排序之后只对根节点和最后的节点进行交换,交换后只有根节点是无序的,其他都是有序的;
*/
public static void duipaixu(int[] ins){
int temp;
int len=ins.length;
for(int i=len/2-1;i>=0;i--){
tiaozheng(ins,i,len);
}
for(int j=len-1;j>0;j--){
temp=ins[j];
ins[j]=ins[0];
ins[0]=temp;
tiaozheng(ins,0,j);
}
}
public static void tiaozheng(int[] ins,int i,int len){
int temp=ins[i];
for(int k=i*2+1;k<len;k=k*2+1){
if(k+1<len && ins[k]<ins[k+1]){
k++;
}
if(ins[k]>temp){
ins[i]=ins[k];
i=k;
}else{
break;
}
ins[i]=temp;
}
}
各种排序算法的比较和总结
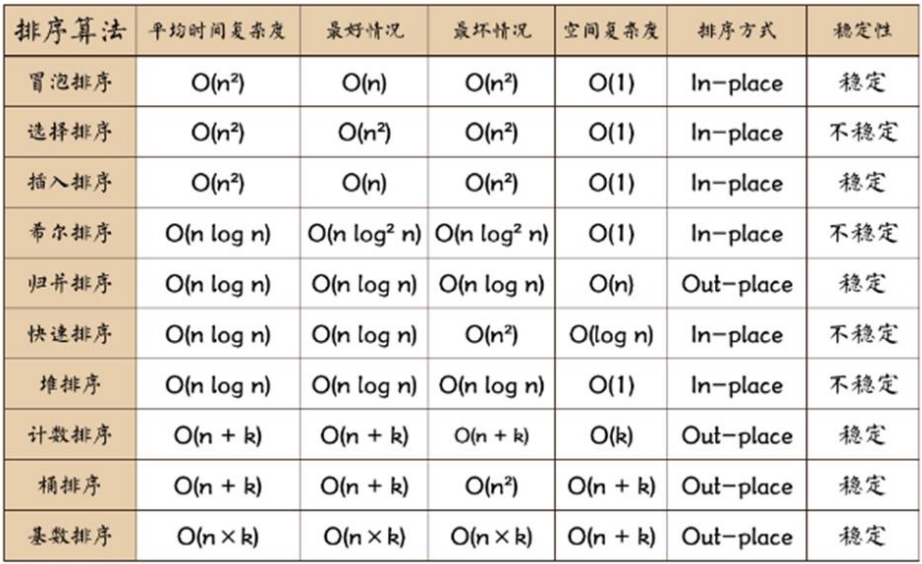
相关术语解释:
1、稳定:如果a原本在b前面,而a=b,排序后a依然在b的前面;
2、时间复杂度:一个算法执行所耗费的时间;
3、空间复杂度:运行完一个程序所需内存的大小;
4、n:数据规模;
5、k:“桶”的个数;
6、IN-PLAVE:不占用额外内存;